Terms:
- Topic: a named data fee that data can be written to and read from.
- Log: The data structure used to store a topic’s data. The log is partitioned. An immutable sequence of data records.
- Partition: A section of a topic’s log
- Offset The sequential and unique Id of a data record within a partition.
- Producer: Something that writes data to a topic
- Consumer: Something that reads data from a topic
- Consumer group: A group of multiple consumers. Normally, multiple consumers. Normally, multiple consumers can all consume the same record from a topic, but only one consumer in a consumer group will consume reach a record.
Topic
Topics are at the core of everything you can do in Kafka.
A topic is a data feed to which data records are published and from which they can be consumed. [write record and read record]
When we think of Apache Kafka as messaging system, we have application called publisher which is writing the data to Topic, and then another application called subscriber which is reading the data from the Topic.
We can have many Topics in the Apache Kafka Cluster. This is Know as publisher/subscriber messaging, or simply pub/sub model.
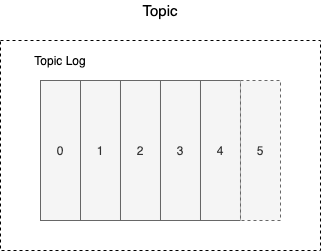
The Topic Log
The Topic log is the underline the data structure of the Apache Kafka topic.
Kafka topics each maintain a log.
The log is an ordered, immutable list of data records. The log for a Kafka topic is usually divided into multiple partitions. This is what allows Kafka to process data efficiently and in a scalable fashion.
Each record in a partition has a sequential, unique ID called an offset
immutable: if you publish data to the apache Kafka Topic, it is going to add the end of log which means the log is in ordered based on the log is received, also, the log is immutable which means i can not make change the log after you publish a data.
New data to the log – publish the new records – added the data in Topic Log which is immutable.
Partition
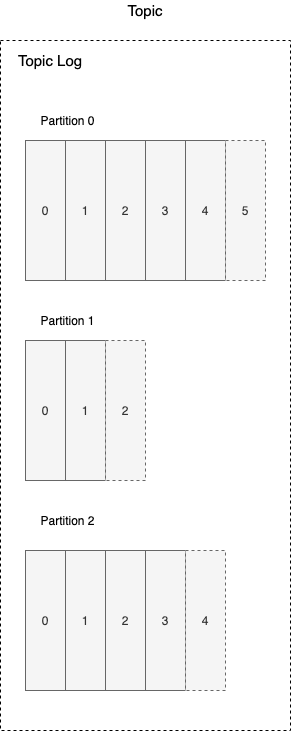
Partitions are really about scalability. We could have a multi-server Kafka cluster. Those Partitions could assign different Brokers. This is not mandatory. They could assign the same Broker. The real purpose of the partition is to allow scalability.
Offest: 0, 1, 2, 3 in Topic partition.
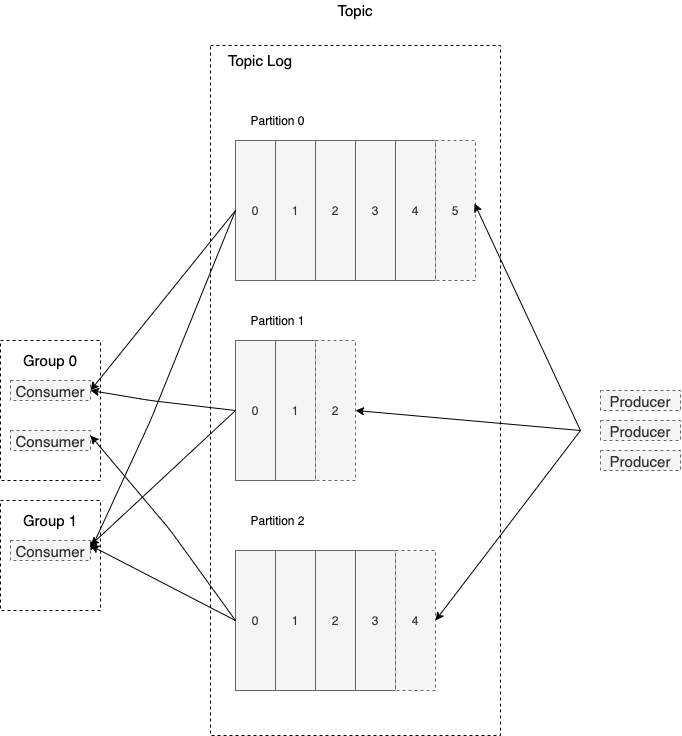
Producers
The producer is an external application that is writing the data to our Kafka Topic. You can have any number of producers that are publishing data to a particular partition.
A Producer is a publisher in the pub/sub-model. The producer is simply an application that communicates with the cluster and can be in a separate process or on a different server.
Producers write data records to the Kafka topic. For each new record, the producer determines which partition to write to, often in a simple round-robin fashion. You can customize this to use a more sophisticated algorithm for determining which topic to write a new record to.
Consumers
Consumer is receiving and reading the data from the topic.
A consumer is the subscriber in the pub/sub model. Like producers, consumers are external applications that can be in a separate process or on a different server from Kafka itself.
Consumers read data from Kafka topics. Each consumer controls the offset it is currently reading for each partition, and consumers normally read records in order based on the offset. You can have any number of consumers for a topic, and they can all process the same records.
Records are not deleted when they are consumed. They are only deleted based upon a configurable retention period.
Consumer Groups
By default, all consumers will process all records, but what if you want to scale your record processing so that multiple instances can process the data without two instances processing the same record?
You can place consumers into Consumer groups. Each record will be consumed by exactly one consumer per consumer group.
Which consumer groups, Kafka dynamically assigns each partition to exactly one consumer in the groups. If you have more consumers than partitions, some of the consumers will be idle and will not process records.