Kafka is designed with fault tolerance in mind. As a result, it includes built-in support for replication.
Replication
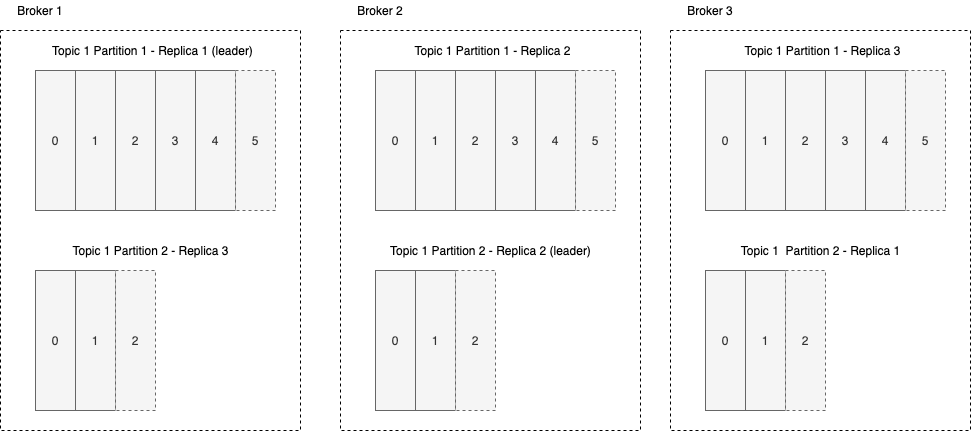
Replication means storing multiple copies of any given piece of data.
In Kafka, every topic is given a configurable replication factor.
The replication factor is the number f replicas that will be kept on different brokers for each partition in the topic.
kubectl exec -it kafka-client -- kafka-topics.sh --bootstrap-server osckorea-kafka-0.osckorea-kafka-headless:9092 --create --topic test-topic --partitions 3 --replication-factor 2
Created topic test-topic.Create topic
- name= test-topic
- partitions 3
- replication-factor 2
kubectl exec -it kafka-client -- kafka-topics.sh --bootstrap-server osckorea-kafka-0.osckorea-kafka-headless:9092 --describe --topic test-topic
# Topic: test-topic PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
# Topic: test-topic Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
# Topic: test-topic Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
# Topic: test-topic Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2- Replicas: 3,1
- Replicas: 1,0
- Replicas: 0,2
- is actually broker id so, which mean first partition is in broker three and broker one.
- Leader: 3
- Leader: 1
- Leader: 0
- is also broker id so, which mean first partition‘s leader is broker three
Leaders
In order to ensure that messages in a partition are kept in a consistent order across all replicas, Kafka chooses a leader for each partition.
The leader handles all reads and writes for the partition. The leader is dynamically selected and if the leader goes down, the cluster attempts to choose a new leader election.
In-Sync Replicas
Kafka maintains a list of In-Sync Replicas (ISR) for each partition.
ISRs are replicas that are up-to-date with the leader. If a leader dies, the new leader is elected from among the ISRs.
By default, if there are no remaining ISRs when a leader dies, Kafka waits until one becomes available. This means that producers will be on hold until a new leader can be elected.
You can turn on unclean leader election, allowing the cluster to elect a non-in-sync replica in the scenario.