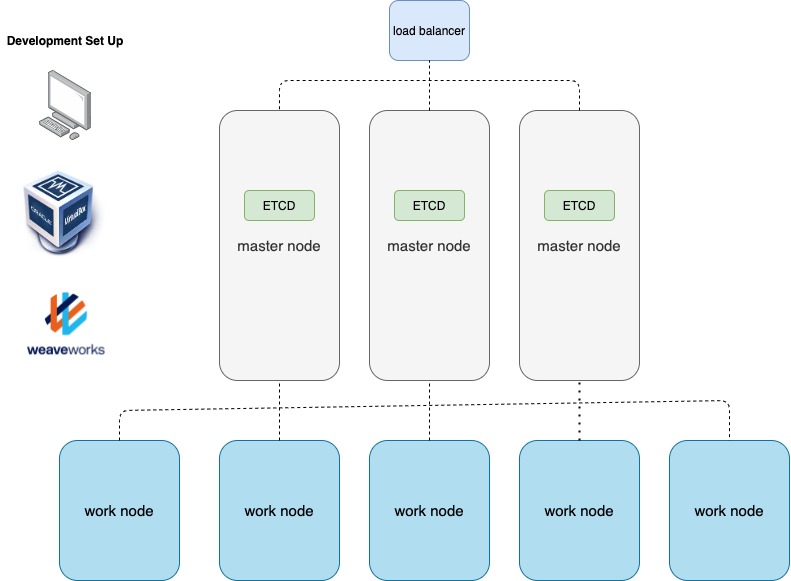
What is ETCD?
ETCD is a distributed reliable Key-value store that is Simple, Secure & Fast.
Distributed?
We had ETCD on a single server. However, it is a database and may be storing critical data. So it is possible to have your datastore across multiple servers. If You have three servers, all running etcd, and all maintaining an identical copy of the database, you lose one you still have two copies of the data.
How does it ensure the data on all the nodes are consistent?
You can write to any instance and read the data from any instance. ETCD ensures that the same consistent copy of the data is available on all instances at the same time.
So, how does it do that?
read is easy. Since the same data is available across all nodes, you can easily read it from any node.
Write needs a leader, What if two write requests come in on two different instances? Which one goes through? ETCD does not process the writes on each node. Only one of the instances is responsible for processing the writes. Internally, the two nodes elect a leader among them. Of the total instances, one node becomes the leader and the other node becomes the followers. If the writes come in through any of the follower nodes, then they forward the writes to the leader internally, and then the leader processes the writes. The leader ensures that copies of the written and distributed to other instances in the cluster.
How do they elect the leader among themselves?
ETCD implements distributed consensus using RAFT protocol. For example, if you have a three-node cluster when the cluster is setup we have three nodes that do not have a leader elected. RAFT algorithms use random timers for initiating requests. If the leader is elected, it sends out a notification at regular intervals to other masters informing them that it is continuing to assume the role of the leader. In case the other nodes do not receive a notification from the leader at some point in time which could either be due to the leader going down or losing network connectivity the nodes initiate a re-election process among themselves and a new leader is identified.
ETCD cluster is highly available. So, even if you lose a node it should still function. If a new write comes in but one of the nodes is not responding. a leader can write to only two nodes in the cluster. Is the writing considered to be complete? A write is considered to be complete if it can be written on the majority of the nodes in the cluster. Also, the third node is to come online then the data is copied to that as well.
Majority(Quorum) = N/2 +1
The minimum number of nodes that must be available for the cluster to function properly or make a successful right.
| Nodes (Instances) | Quorum |
| 1 | 1 |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 6 | 4 |
| 7 | 4 |
Which is why it is recommended to have a minimum of three instances in an ETCD Cluster.
When deciding on the number of master nodes, it is recommended to select an odd number as in tables 3, 5, 7. Even number of nodes there is the possibility of the cluster failing during a network segmentation.
Once installed and configured use the etcdctl utility to store and retrieve data. etcdctl utility has two API versions. V2 and V3. Version 2 is the default. So set an environment variable to use V3.
$ export ETCDCTL_API=3
$ etcdctl put name joe
$ etcdctl get name
$ etcdctl get / --prefix --keys-onlyAll the even number of nodes is out of scope. So, we are left with 3, 5, 7 or above. Three is a good start. Considering the environment the fault tolerance requirements and the cost that you can bear.